神经网络构成
+ 输入层
+ 隐层
+ 输出层
+ 每一层由多个神经元组成
+ w 是权重,b 是偏置,h 是激活函数
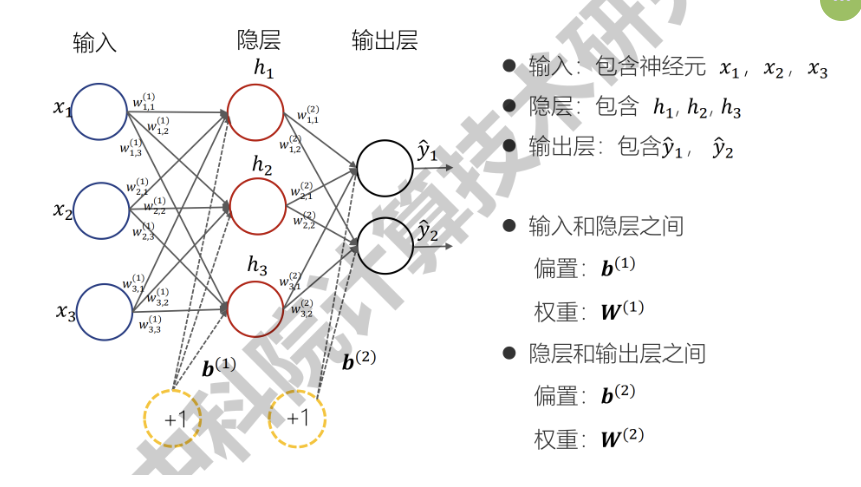
层层递进,可以理解为朝着更具体的方向深入(比如:形状 -> 轮廓 -> 图像)
损失函数
设置不同的函数形式,反映神经网络的输出值与数据的真实值之间的差异。
常用损失函数:
+ 均方差损失函数
+ 交叉熵损失函数
激活函数
在神经网络中,除了层内的线性函数转化,还需要在隐层的每个神经元设置对中间输出的一个非线性函数转化,进而引入非线性因素。这个非线性函数就是激活函数。
常用激活函数:
+ sigmoid
+ RELU
反向传播
根据神经网络正向传播计算损失函数,再通过链式求导,沿着相反方向计算每个权重的梯度,根据梯度来调整权重,使得在下一次正向传播能得到与真实值更接近的输出。
神经网络运行的整个过程就是正向传播与反向传播的迭代
泛化能力
对于一个训练好的模型,在遇到它从未见到过的数据时,可以准确作出预测的能力,就是泛化能力。
正则化
抑制过拟合现象的一系列方法
鲁棒性
具体指:在存在干扰,恶劣的条件下,依然能保持正常稳定的能力。
在深度学习中指:不考虑测试数据集,而看模型在真实数据集下的工作能力。
与过拟合联系紧密
数据集
深度学习中的数据集分类:
+ 训练集:训练模型参数
+ 验证集:确定一些神经网络超参数
+ 测试集:评估模型训练效果
交叉验证
将数据集分成多份,将每一份数据都作为测试集一次,剩下的多份作为训练集,进行多轮验证,取平均值作为最终结果,这个过程就是交叉验证。
分成 k 份,称作 k 折交叉验证。
Pipeline
流水线,可以理解为一种整体方案
相当于对所有工作进行一个整体封装(里面有多个任务按序执行,上一步的输出是下一步的输入),使执行整个流程时只需要启动Pineline对象即可。
优点:能够保证训练集和测试集处理的一致性。
eg:
# 定义一个流水线:先标准化,再跑支持向量机分类
pipe = Pipeline([
('scaler', StandardScaler()), # 步骤1:标准化
('svc', SVC()) # 步骤2:模型
])Baseline
基线,可以理解为基础模型,用于作为基准来判断对模型的改进是否有效
可以理解为在对数据做 “精进处理” 之前先用一些简单基础的方式验证数据是否合格
norminal / ordinal data
都是分类变量;区别在于:norminal 的类别值无高低之分,而 ordinal 有。
Mutual information --- 互信息,MI
衡量两个变量之间的“信息共享”量,表示知道特征 X 后能减少多少对目标 Y 的不确定性。
在特征工程中的用途:特征筛选:计算每个特征与目标的 MI,选取高 MI 的特征。
回归问题的评估度量标准
Mean absolute error --- 平均绝对误差,MAE
用于衡量预测值与实际值之间的平均绝对差异
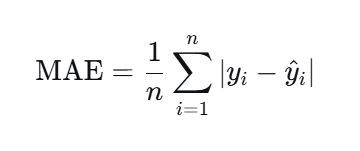
Mean square error --- 均方绝对误差,MSE
每一对预测值与实际值平方再求和
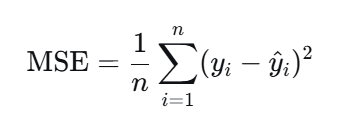
Root mean square error --- 开方绝对误差,RMSE
MSE开方后的值
决定系数 r2

评论